原文链接 : Reverse Engineering One Line of JavaScript
原文作者 : Alex
译文出自 : 众成翻译
译者 : yangzj1992
首发于: 众成翻译
不久前,我看到有人提了个问题,能否有人将下面这行 JS 代码进行逆向分析。
1
| <pre id=p><script>n=setInterval("for(n+=7,i=k,P='p.\\n';i-=1/k;P+=P[i%2?(i%2*j-j+n/k^j)&1:2])j=k/i;p.innerHTML=P",k=64)</script>
|
这行代码的效果如下所示,它是一个大小仅为 128b 的光线追踪挡板 Demo 。你也可以访问这里查看效果。这行代码的作者是p01, 发布于Pouet.net。你可以访问他的网站看到更多有趣的 Demo。

下面我们试着对这行代码进行一下逆向分析。
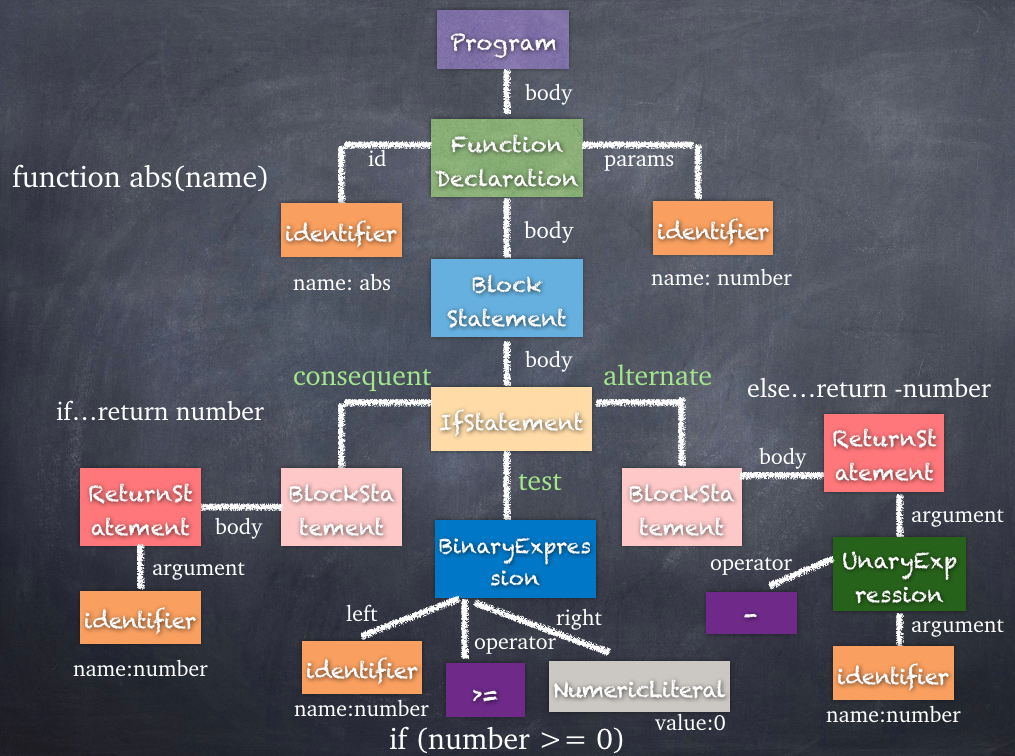
第一部分,使代码可读。
首先,我们将 HTML 和 JS 代码分离。这里我们保留相关的 id 指向。
1 2 | <script src="code.js"></script> <pre id="p"></pre> |
这里我们注意到有个变量 k。我们将它置顶申明,并重命名为 delay。
1 2 3 | var delay = 64; var draw = "for(n+=7,i=delay,P='p.\\n';i-=1/delay;P+=P[i%2?(i%2*j-j+n/delay^j)&1:2])j=delay/i;p.innerHTML=P"; var n = setInterval(draw, delay); |
var draw 由于是一个字符串,它会被 setInterval 用 eval() 方法执行(setInterval 可以接受一个 function 或是 string 来执行)。所以这里我们将它重写成一个真实的 function。
另外这里还对元素 p 进行了直接的 DOM 操作,这里我们用 JS 获取这个 id 来重新书写,让它更加易懂。
1 2 3 4 5 6 7 8 9 | var delay = 64; var p = document.getElementById("p"); // < --------------- // var draw = "for(n+=7,i=delay,P='p.\\n';i-=1/delay;P+=P[i%2?(i%2*j-j+n/delay^j)&1:2])j=delay/i;p.innerHTML=P"; var draw = function() { for (n += 7, i = delay, P = 'p.\n'; i -= 1 / delay; P += P[i % 2 ? (i % 2 * j - j + n / delay ^ j) & 1 : 2]) { j = delay / i; p.innerHTML = P; } }; var n = setInterval(draw, delay); |
接下来,我们将变量 i,p, j 也作提前声明。
1 2 3 4 5 6 7 8 9 10 11 12 13 | var delay = 64; var p = document.getElementById("p"); // var draw = "for(n+=7,i=delay,P='p.\\n';i-=1/delay;P+=P[i%2?(i%2*j-j+n/delay^j)&1:2])j=delay/i;p.innerHTML=P"; var draw = function() { var i = delay; // < --------------- var P ='p.\n'; var j; for (n += 7; i > 0 ;P += P[i % 2 ? (i % 2 * j - j + n / delay ^ j) & 1 : 2]) { j = delay / i; p.innerHTML = P; i -= 1 / delay; } }; var n = setInterval(draw, delay); |
然后,我们将 for 循环转为 while 循环,将 for 循环中间的条件语句作为条件,其他的语句放到 while 循环的内外部。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | var delay = 64; var p = document.getElementById("p"); // var draw = "for(n+=7,i=delay,P='p.\\n';i-=1/delay;P+=P[i%2?(i%2*j-j+n/delay^j)&1:2])j=delay/i;p.innerHTML=P"; var draw = function() { var i = delay; var P ='p.\n'; var j; n += 7; while (i > 0) { // <---------------------- //Update HTML p.innerHTML = P; j = delay / i; i -= 1 / delay; P += P[i % 2 ? (i % 2 * j - j + n / delay ^ j) & 1 : 2]; } }; var n = setInterval(draw, delay); |
接下来我们展开三元表达式。
这里 i % 2 的作用是判断 i 是否为偶数,如果是偶数,那么将会返回 2,否则返回 (i % 2 * j - j + n / delay ^ j) & 1。
而这一堆式子也将会作为 P 的 index 进行处理。 即 P += P[index];
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | var delay = 64; var p = document.getElementById("p"); // var draw = "for(n+=7,i=delay,P='p.\\n';i-=1/delay;P+=P[i%2?(i%2*j-j+n/delay^j)&1:2])j=delay/i;p.innerHTML=P"; var draw = function() { var i = delay; var P ='p.\n'; var j; n += 7; while (i > 0) { //Update HTML p.innerHTML = P; j = delay / i; i -= 1 / delay; let index; let iIsOdd = (i % 2 != 0); // <--------------- if (iIsOdd) { // <--------------- index = (i % 2 * j - j + n / delay ^ j) & 1; } else { index = 2; } P += P[index]; } }; var n = setInterval(draw, delay); |
这里我们接下来注意到与运算符 & 1。
(i % 2 * j - j + n / delay ^ j) & 1,这段代码可以巧妙地去比较一个数是否为奇偶,它的原理其实是数值转换为二进制进行与运算返回的十进制结果。
1 2 3 4 5 6 | 0 & 1 // 0 1 & 1 // 1 2 & 1 // 0 3 & 1 // 1 3 & 2 // 2 8 & 8 // 8 |
然后我们再次对变量进行重命名整合。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | var delay = 64; var p = document.getElementById("p"); // var draw = "for(n+=7,i=delay,P='p.\\n';i-=1/delay;P+=P[i%2?(i%2*j-j+n/delay^j)&1:2])j=delay/i;p.innerHTML=P"; var draw = function() { var i = delay; var P ='p.\n'; var j; n += 7; while (i > 0) { //Update HTML p.innerHTML = P; j = delay / i; i -= 1 / delay; let index; let iIsOdd = (i % 2 != 0); if (iIsOdd) { let magic = (i % 2 * j - j + n / delay ^ j); let magicIsOdd = (magic % 2 != 0); // &1 < -------------------------- if (magicIsOdd) { // &1 <-------------------------- index = 1; } else { index = 0; } } else { index = 2; } P += P[index]; } }; var n = setInterval(draw, delay); |
由于这里 P ='p.\n'; 而我们的 index 的值为:0, 1, 2。对应即有:
1 2 3 | P[0] = 'p' P[1] = '.' P[2] = '\n' |
所以这里我们还可以用 switch 重写代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | var delay = 64; var p = document.getElementById("p"); // var draw = "for(n+=7,i=delay,P='p.\\n';i-=1/delay;P+=P[i%2?(i%2*j-j+n/delay^j)&1:2])j=delay/i;p.innerHTML=P"; var draw = function() { var i = delay; var P ='p.\n'; var j; n += 7; while (i > 0) { //Update HTML p.innerHTML = P; j = delay / i; i -= 1 / delay; let index; let iIsOdd = (i % 2 != 0); if (iIsOdd) { let magic = (i % 2 * j - j + n / delay ^ j); let magicIsOdd = (magic % 2 != 0); // &1 if (magicIsOdd) { // &1 index = 1; } else { index = 0; } } else { index = 2; } switch (index) { // P += P[index]; <----------------------- case 0: P += "p"; // aka P[0] break; case 1: P += "."; // aka P[1] break; case 2: P += "\n"; // aka P[2] } } }; var n = setInterval(draw, delay); |
现在我们来梳理 var n = setInterval(draw, delay);。因为 setInterval 返回一个从 1 开始的整数 ID 。并在每次 setInterval 方法被调用时依次递增。(这个 ID 可以被用于 clearInterval 等方法。)在我们的例子中,setInterval 只被调用了一次,所以 n 被设置为 1。
此外,我们把 delay 重命名为 DELAY 以作为常量。
最后,我们对 i % 2 * j - j + n / DELAY ^ j 进行排序,由于 ^ 位异或运算符的优先级较低。所以加上括号后整理如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | const DELAY = 64; // approximately 15 frames per second var n = 1; var p = document.getElementById("p"); // var draw = "for(n+=7,i=delay,P='p.\\n';i-=1/delay;P+=P[i%2?(i%2*j-j+n/delay^j)&1:2])j=delay/i;p.innerHTML=P"; /** * Draws a picture * 128 chars by 32 chars = total 4096 chars */ var draw = function() { var i = DELAY; // 64 var P ='p.\n'; // First line, reference for chars to use var j; n += 7; while (i > 0) { j = DELAY / i; i -= 1 / DELAY; let index; let iIsOdd = (i % 2 != 0); if (iIsOdd) { let magic = ((i % 2 * j - j + n / DELAY) ^ j); // < ------------------ let magicIsOdd = (magic % 2 != 0); // &1 if (magicIsOdd) { // &1 index = 1; } else { index = 0; } } else { index = 2; } switch (index) { // P += P[index]; case 0: P += "p"; break; case 1: P += "."; break; case 2: P += "\n"; } } //Update HTML p.innerHTML = P; }; setInterval(draw, 64); |
你可以在这里看到最后的代码。
第二部分,理解代码。
在 draw() 函数第一次执行时 i 被 var i = DELAY; 初始化为 64,并在每次循环中被 i -= 1 / DELAY; 进行逐次 1/64 的递减。直到 i > 0 时结束(循环 64 * 64 次)
而我们的图像则是由 32 行组成,每行包含了 128 个字符。这里我们可以注意到我们会对 i 进行奇偶判断:let iIsOdd = (i % 2 != 0) 当 i 为偶数时,总计会发生 32 次。(即 64、62、60...等)。此时 index 将被赋值为 2。此时通过 P += "\n"; 来添加新的一行。剩下的 127 次循环产生的字符即为 p 或 .。
由代码可知,当 ((i % 2 * j - j + n / DELAY) ^ j); 为奇数时。我们会添加 .,反之会添加 p。
这里问题的关键来了,这串式子什么时候分别为奇偶呢?在我们研究前,我们可以做一个实验,让我们从 let magic = ((i % 2 * j - j + n / DELAY) ^ j); 中移除 + n/DELAY。刷新页面后,我们获得了一份静止的图像输出。
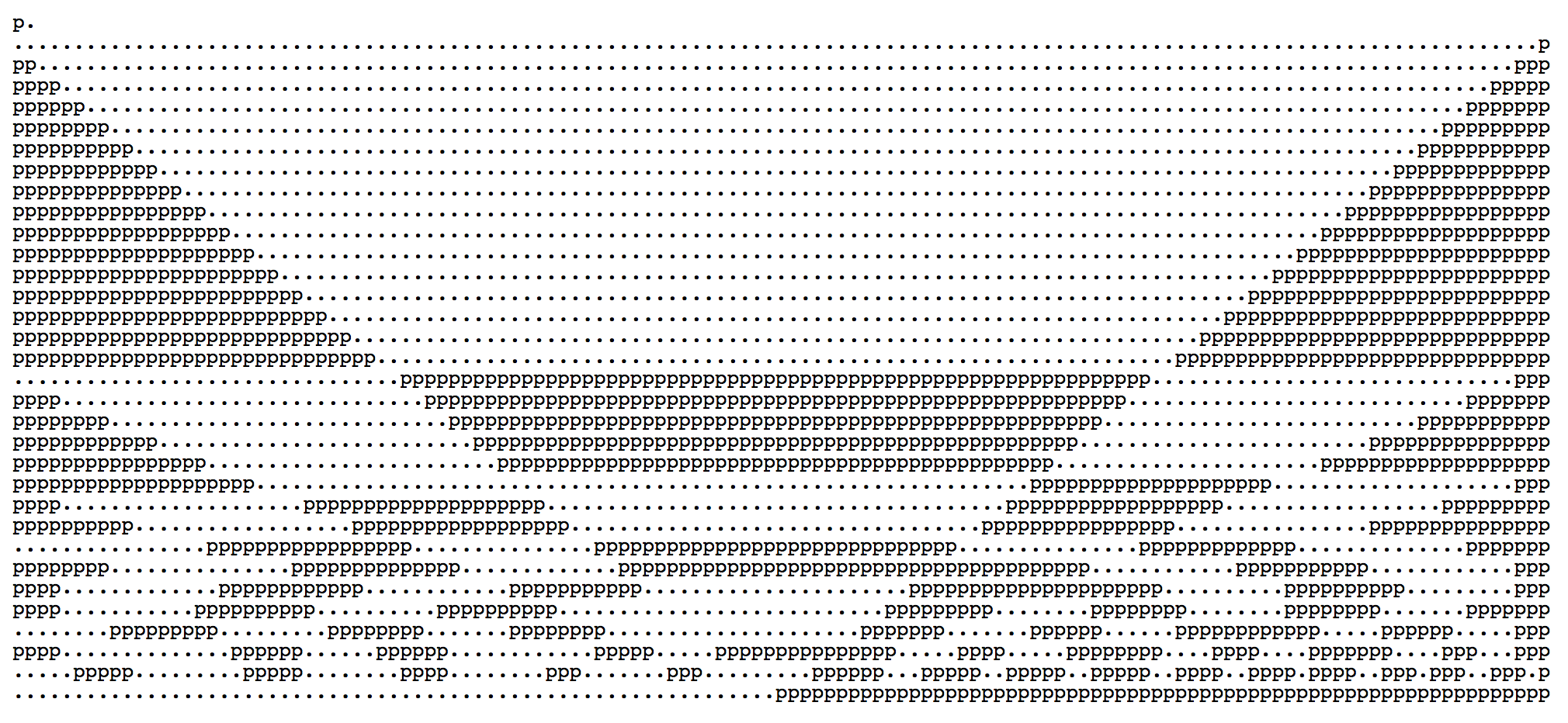
那么,我们就先在移除 + n/DELAY 的情况下进行探讨。对于 (i % 2 * j - j) ^ j 因为在每次循环中有: j = DELAY / i; 所以我们可以将式子简化为一元式:(i % 2 * 64/i - 64/i) ^ 64/i。
这里我们借助一个在线的图表生成工具来帮忙绘制函数。
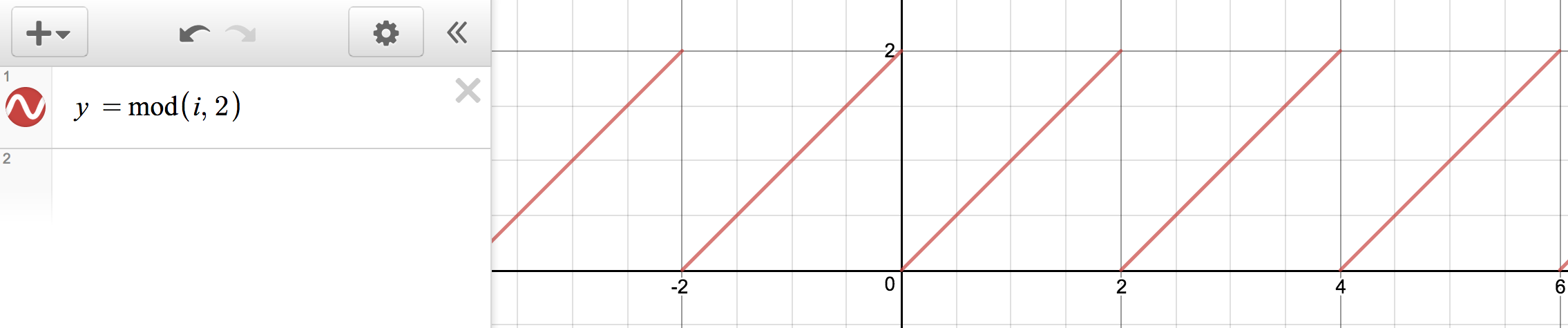
例如,首先我们要绘制的 i % 2,它的展示为下图所示的重复一次函数片段,y 值的范围在 0 到 2 之间。
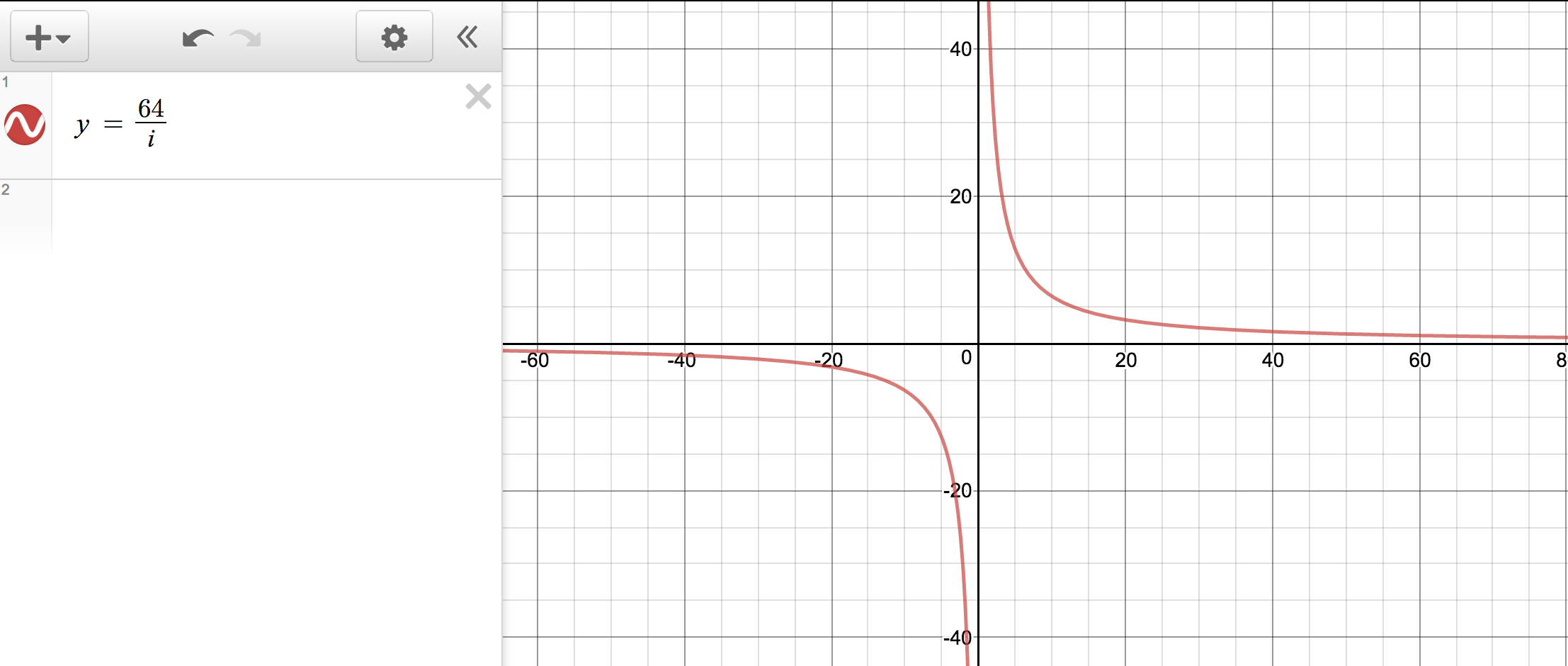
如果我们绘制 64/i ,所对应的图表展示如下:
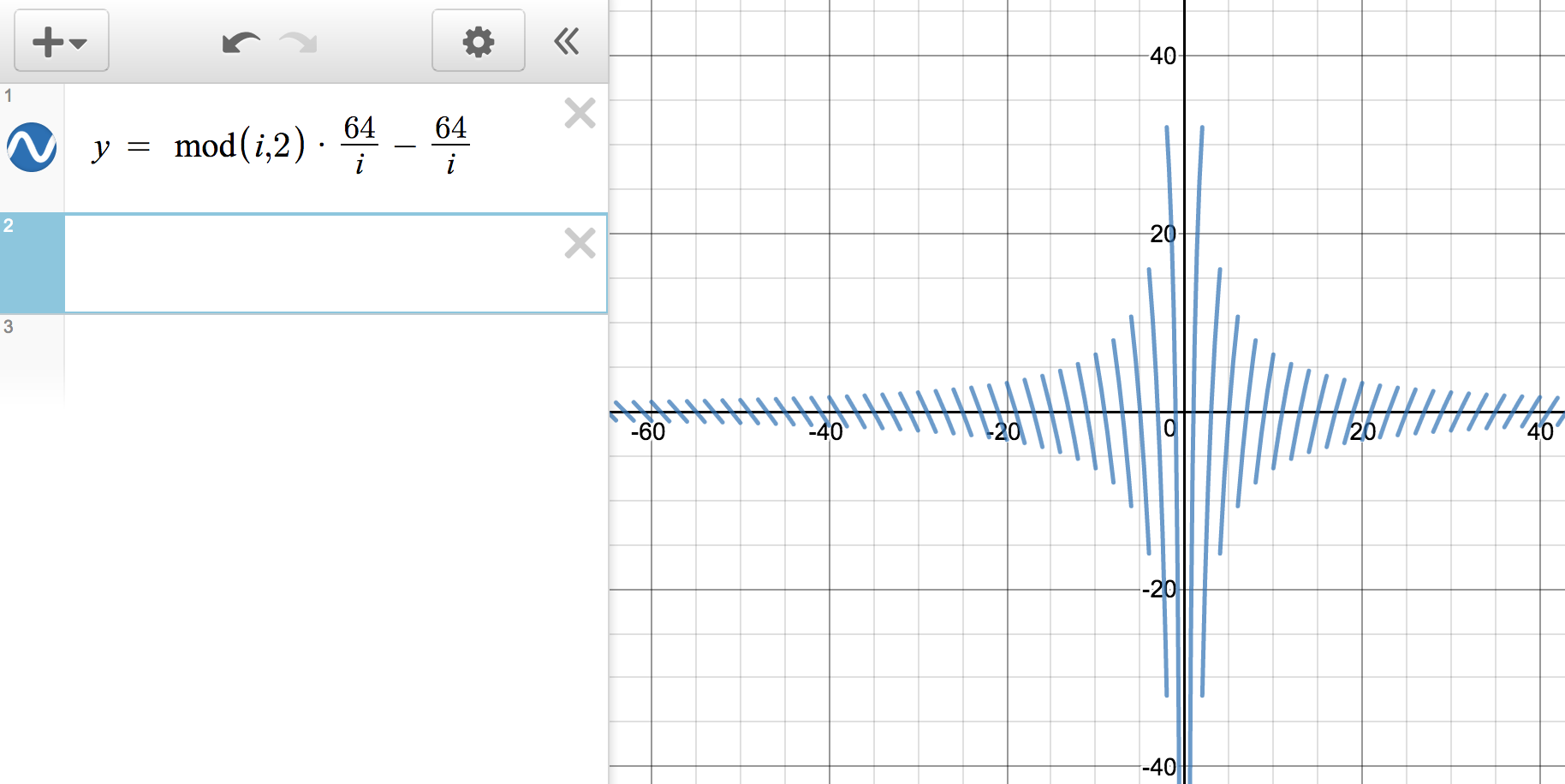
现在我们将式子结合起来,绘制图如下:
将两个函数绘制在一张图上,绘制图如下:
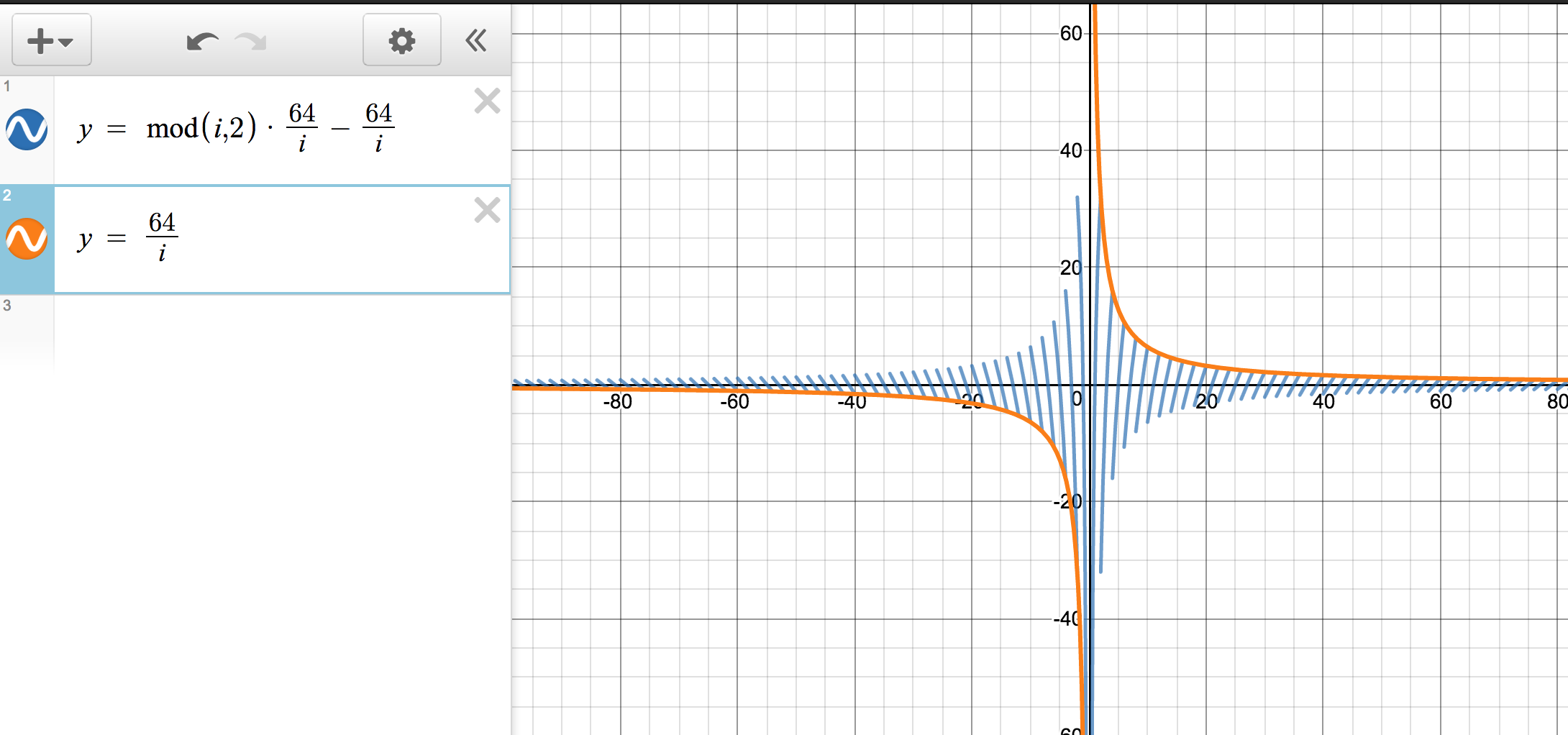
这些图表是什么意思
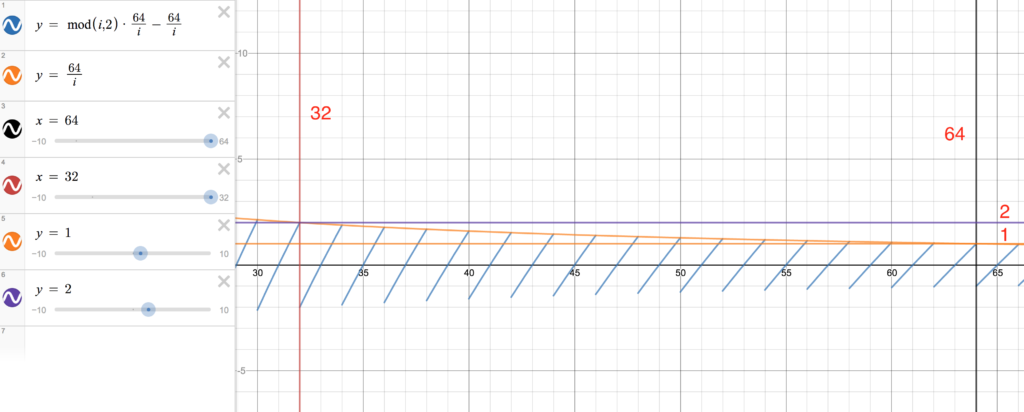
现在让我们着力观察图表的前16行,即 i 值的范围是从 64 到 32。
通过 JS 的 XOR (位异或)运算符的计算规则,当你的位运算两端都为 0 或 1 时,将返回 0 ,两端不同时为 1。同时如果你的数是小数的话,将会抛弃小数部分进行计算。
1 2 3 4 5 | First Second Result 1 1 1 1 0 1 0 1 1 0 0 0 |
异或运算的窍门:对两个数进行三次异或运算,可以互换他们的值,不需要引入临时变量。
异或运算也可以用来取整
1.23^0 //1,3.5^0 //3当负数与整数进行异或运算时。负数先进行补码,取反再加一。正数的原码和补码一致。如,对于 -2:
再转回原码(负数最高位不变,其他位取反,+1,正数不变) = - 3
在 i 值的这个范围内 j 将从 1 开始慢慢的走向 2(即基本为 1.XXX)。这样在另一端也为 1 时,我们将会得到异或计算结果为 0(偶数),最后获得 p 字符输出。
换句话说,每条蓝色的对角线代表着我们 Demo 图表中的一行。因为 j 在这 16 行里总是大于 1 而小于 2。我们得到奇数的唯一办法就是使式子 (i % 2 * j - j)^ j 即 i % 2 * i/64 - i/64 即蓝色的对角线应该处于大于 1 或小于 -1的范围。
通过图我们可以看到,在最右侧的对角线上很少有到大于 1 和小于 -1 的地方。随着对角线往左的描绘,对角线逐渐开始变长。到第 16 行位置对角线到达 -2 到 2 的位置。在 16 行以后,我们从静态 Demo 图上也可以看到图的展示规律变成了另一种模式。
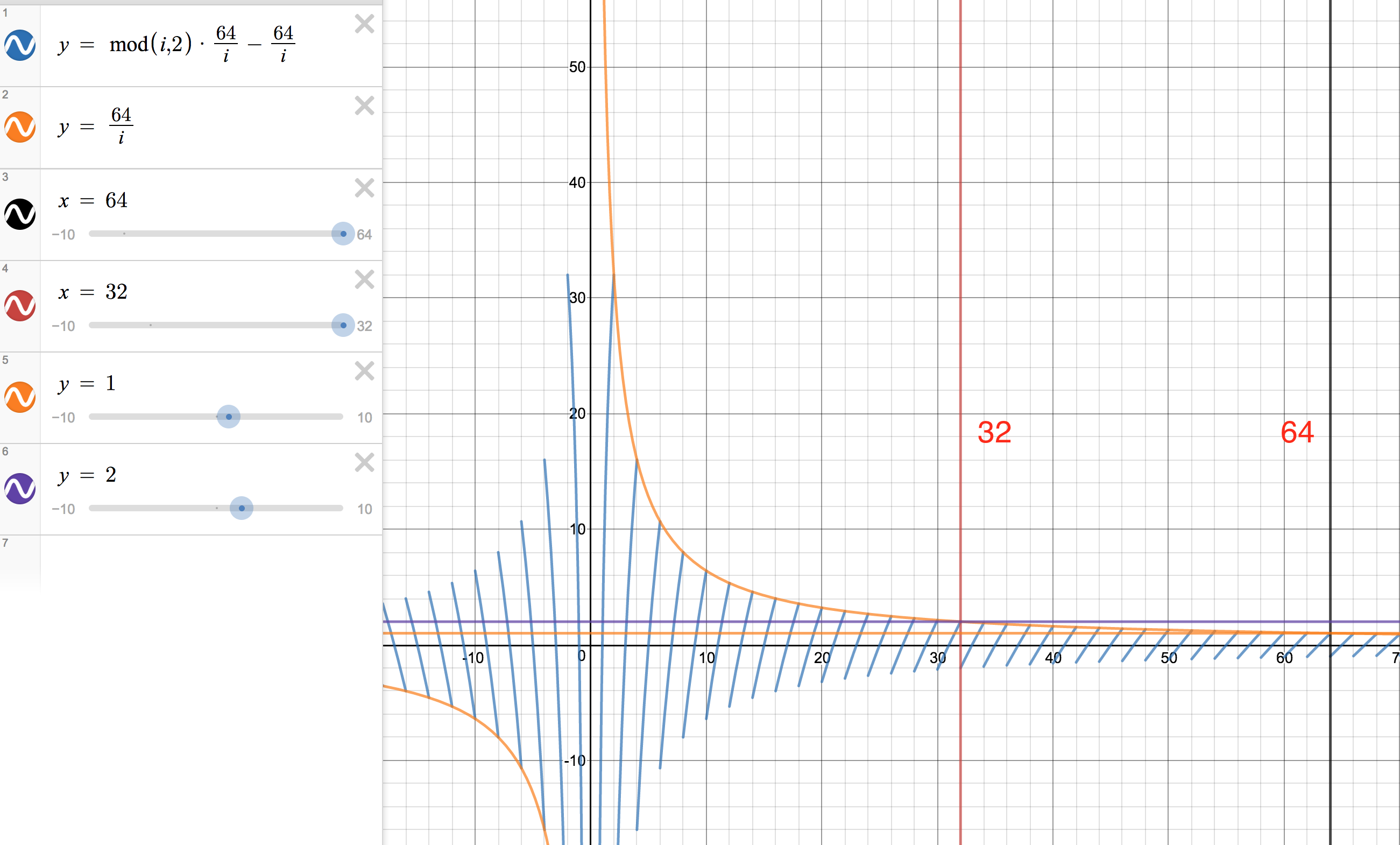
在第 16 行后,j 的值开始大于 2 。这时我们的式子期望也发生了反转,在蓝色对角线大于 2 和小于 -2 时或是 -1 到 1 的范围时式子才能为偶数。这就是为什么在 17 行以后我们能看到更多组 p 的展示。此外如果你仔细观察 Demo 的底部几行,你会注意到它们也并没有遵循同样的展示规则,因为在后面图的波动也越来越大了。
让我们回到 + n/DELAY,通过代码我们可以知道 n 是从 8 开始(从 1 开始并在每次执行 setInterval 时加 7)。
当 n 变成 64 时,此时绘图如下:
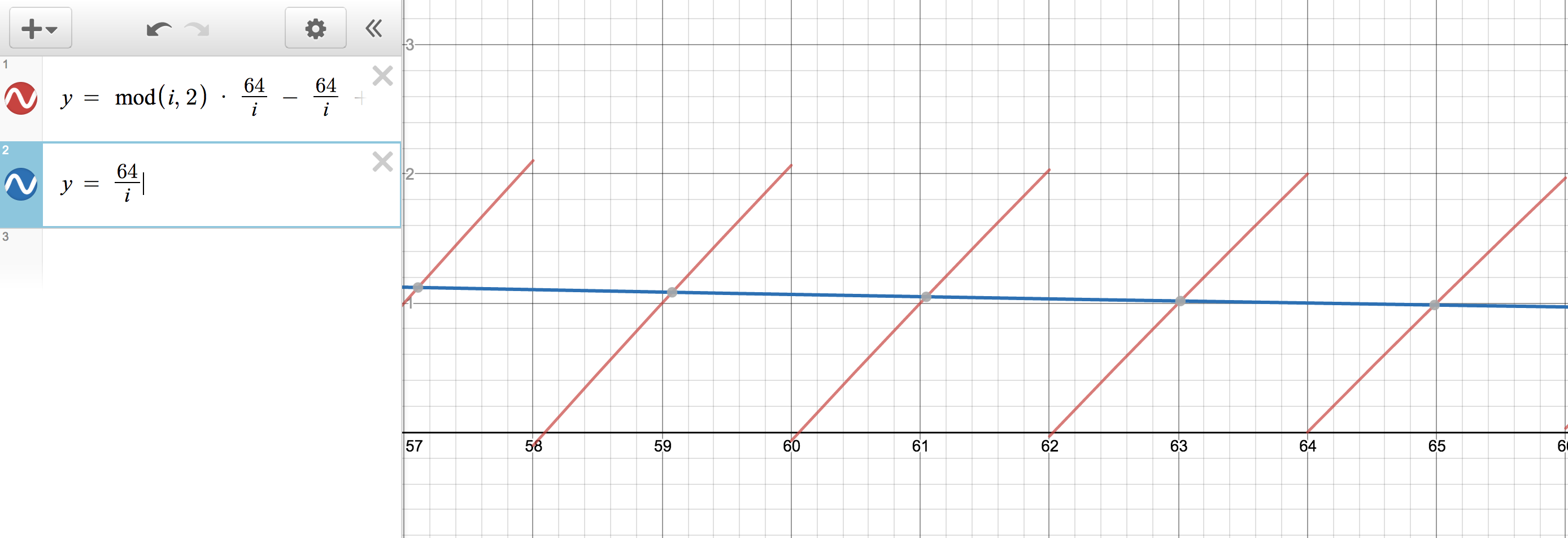
现在 j 的值趋近于 1,x 轴在 62 - 63 上的值为 0.x , 63 - 64 的值为 1.x。可推得在 63 - 64 时对角线的值是 (1 ^ 1 = 0 // even) 添加一串 p,62 - 63 时对角线的值是(1^0 = 1 // odd) 添加一串 .。
此时呈现的 Demo 静态图像如下所示(在 codepen 的 demo 里你可以自行修改 n 值进行测试)。它的第一行正如我们所推测的那样。

当 n 在下一次执行 setInterval,图表产生了如下的轻微变化。
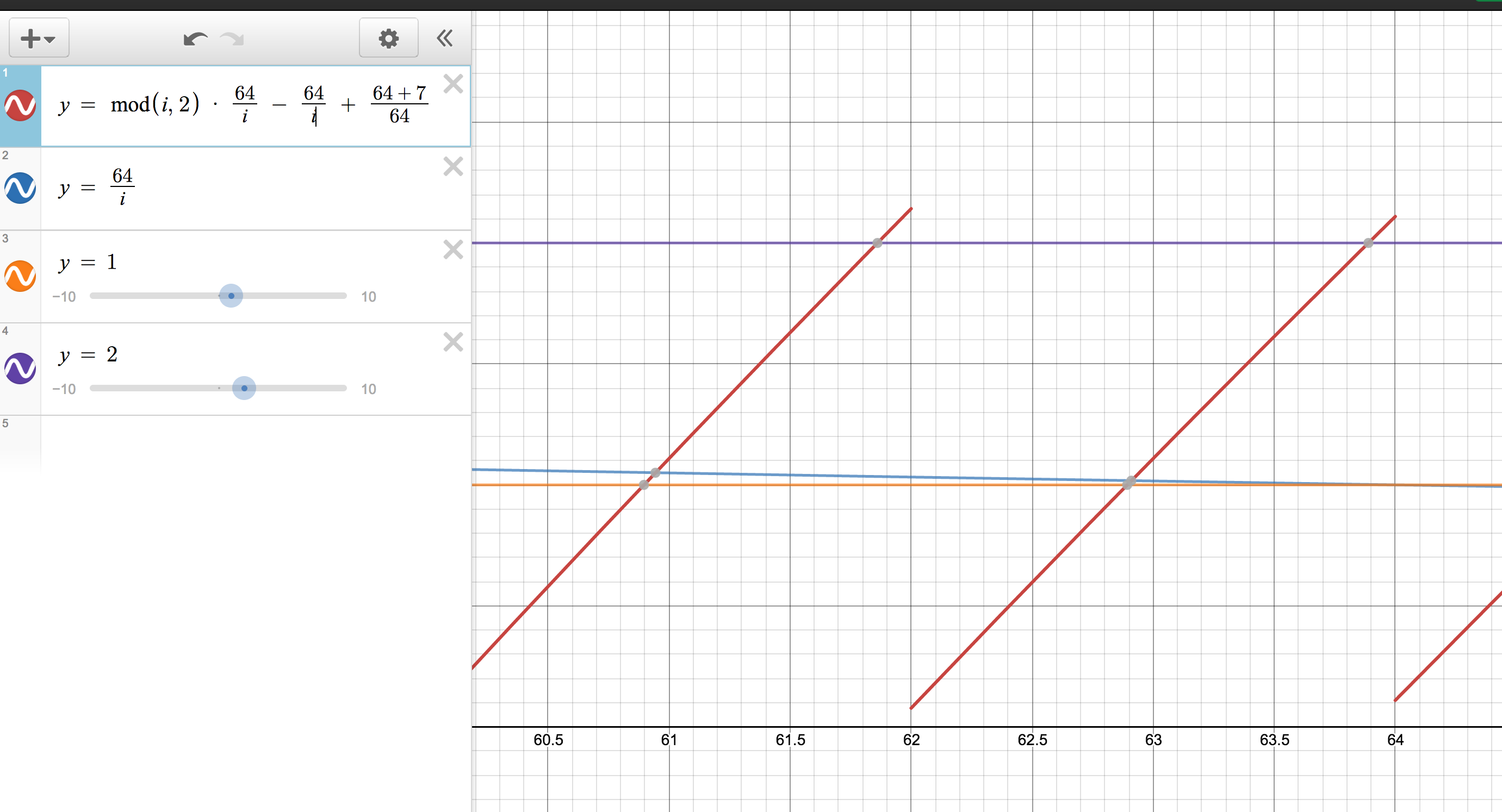
注意,第一行对角线此时增长了 7/64 ≈ 0.1 ,由于 Demo 中 1 行有 128 个字符(对应图表值范围为 2)。相应影响的字符数应该为 0.1 * (128 / 2) = 6.4。我们看一下对应静态图修改后的展示,在第一行中实际移动了 7 个字符,这与我们的猜想也吻合。

再来最后一个例子,这是当 setInterval 被调用 7 次时,n = 64 + 9 * 7。
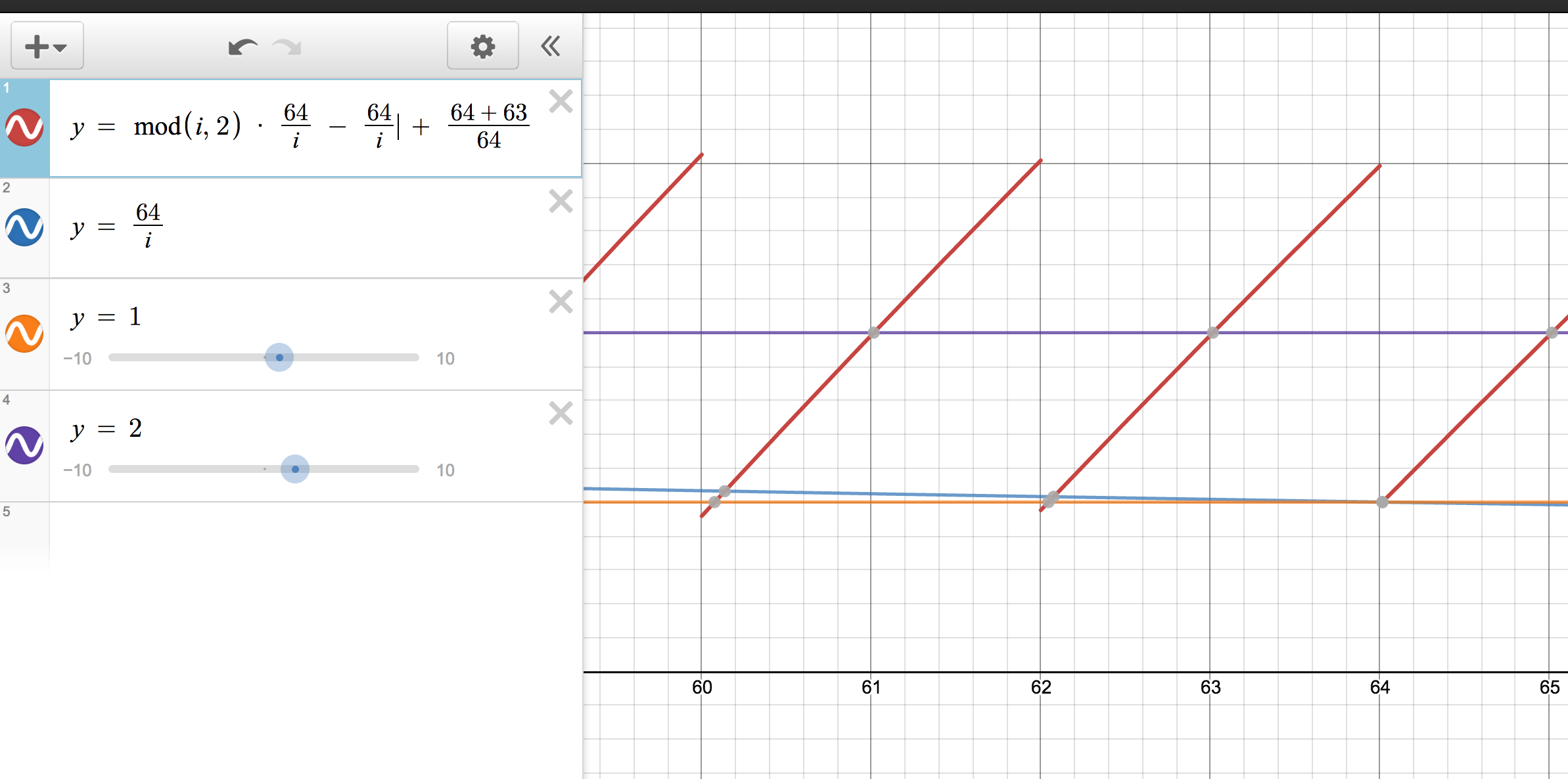
此时第一行 j 依然等于 1。而 63 -- 64 值为 2.x,62 -- 63 值为 1.x。由于 1^2 = 3 // odd - .,1 ^ 1 = 0 //even - p。所以展示效果为一串 . 后面跟随了一串 p。如图所示:
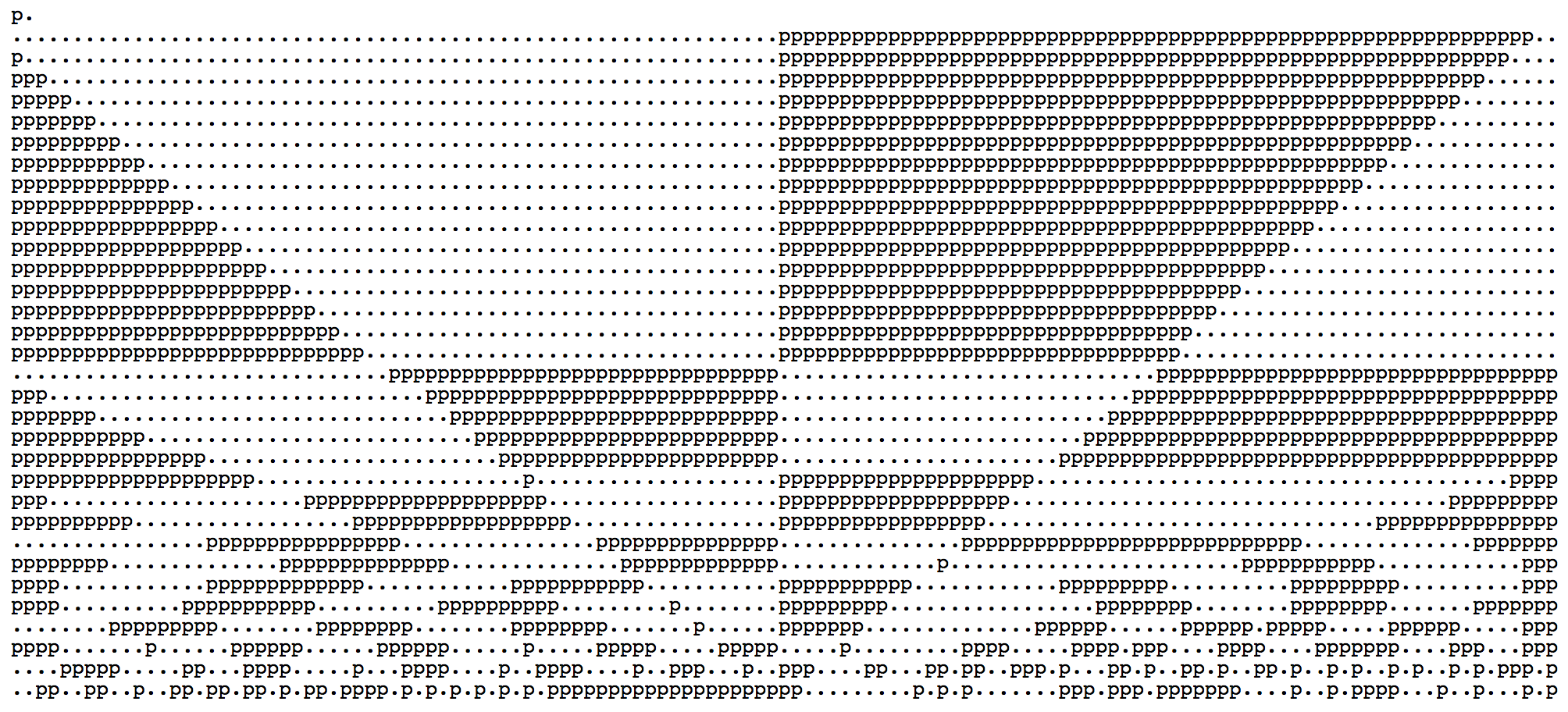
之后 Demo 将会按类似的规则反复进行渲染。
代码的原理大致如此,尽管亲手进行正向压缩简化代码到如此程度确实很难,但是去尝试着理解它也是很有趣的。希望这篇文章能对你有所帮助。
]]>