

JavaScript 排序算法汇总
前言
关于排序算法的有关文章已经很多了,然而网络上用 Javascript 语言来作为示例并详实介绍的文章貌似还是不太多。这里主要是我来尝试自己针对网上各式的排序算法进行一份详实的个人总结,从而温故知新。
基本概念
算法优劣评价术语
稳定性
- 稳定:如果
a原本在b前面,而a = b,排序之后a仍然在b的前面; - 不稳定:如果
a原本在b的前面,而a = b,排序之后a可能会出现在b的后面;
排序方式
- 内排序:所有排序操作都在内存中完成,占用常数内存,不占用额外内存。
- 外排序:由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行,占用额外内存。
复杂度
- 时间复杂度: 一个算法执行所耗费的时间。
- 空间复杂度: 运行完一个程序所需内存的大小。
排序算法图片总结
名词解释:
n : 数据规模
k : 桶的个数
| 排序算法 | 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 | 排序方式 | 稳定性 |
|---|---|---|---|---|---|---|
| 冒泡排序 | $O(n^2)$ | $O(n)$ | $O(n^2)$ | $O(1)$ | 内排序 | 稳定 |
| 选择排序 | $O(n^2)$ | $O(n^2)$ | $O(n^2)$ | $O(1)$ | 内排序 | 不稳定 |
| 插入排序 | $O(n^2)$ | $O(n)$ | $O(n^2)$ | $O(1)$ | 内排序 | 稳定 |
| 希尔排序 | $O(n\log n)$ | $O(n(\log_2^2 n))$ | $O(n(\log_2^2 n))$ | $O(1)$ | 内排序 | 不稳定 |
| 归并排序 | $O(n\log n)$ | $O(n\log n)$ | $O(n\log n)$ | $O(n)$ | 外排序 | 稳定 |
| 快速排序 | $O(n\log n)$ | $O(n\log n)$ | $O(n^2)$ | $O(\log n)$ | 内排序 | 不稳定 |
| 堆排序 | $O(n\log n)$ | $O(n\log n)$ | $O(n\log n)$ | $O(1)$ | 内排序 | 不稳定 |
| 计数排序 | $O(n + k)$ | $O(n + k)$ | $O(n + k)$ | $O(k)$ | 外排序 | 稳定 |
| 桶排序 | $O(n + k)$ | $O(n + k)$ | $O(n^2)$ | $O(n + k)$ | 外排序 | 稳定 |
| 基数排序 | $O(n × k)$ | $O(n × k)$ | $O(n × k)$ | $O(n + k)$ | 外排序 | 稳定 |
从分类上来讲:
| 排序算法 | 交换排序 | 冒泡排序 | 快速排序 |
| 选择排序 | 选择排序 | 堆排序 | |
| 插入排序 | 插入排序 | 希尔排序 | |
| 归并排序 | 归并排序 | ||
| 分布排序 | 计数排序 | 桶排序 | 基数排序 |
冒泡排序(Bubble Sort)[1]
算法原理
冒泡排序(Bubble Sort)是一种简单的排序算法。它重复地走访要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换时,此时该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
图解如下:

算法描述与实现
- 具体算法描述如下:
- 比较相邻的元素。如果第一个比第二个大,就交换它们两个;
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;
- 针对所有的元素重复以上的步骤,除了最后一个;
- 重复步骤 $1~3$,直到排序完成。
- 代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | const bubbleSort = (arr) => { let len = arr.length; for(let i = 0;i < len;i++){ for(let j = 0;j < len - 1 - i;j++){ if(arr[j] > arr[j+1]){ let temp = arr[j+1]; arr[j+1] = arr[j] arr[j] = temp; } } } return arr; } let arr = [3,44,38,5,47,15,36,26,27,2,46,4,19,50,48]; console.log(bubbleSort(arr)); //[2, 3, 4, 5, 15, 19, 26, 27, 36, 38, 44, 46, 47, 48, 50] |
改进冒泡排序: 我们设置一个标志性变量
pos,用于记录每趟排序中最后一次进行交换的位置。由于pos位置之后的元素均已交换到位,故在进行下一趟排序时只要扫描到pos位置即可。 这样的优化方式可以在最好情况下把复杂度降到 $O(n)$。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | const bubbleSort2 = (arr) => { let i = arr.length - 1; while(i > 0){ let pos = 0; for(let j = 0; j < i; j++){ if (arr[j] > arr[j+1]){ pos = j; //记录交换的位置 let tmp = arr[j]; arr[j] = arr[j+1]; arr[j+1] = tmp; } } i = pos; //为下一趟排序作准备 } return arr; } |
另外传统冒泡排序中每一趟排序操作只能找到一个最大值或最小值,我们可以考虑利用在每趟排序中进行正向和反向两遍冒泡的方法来一次得到两个最终值(最大者和最小者),从而继续优化使排序趟数几乎减少一半。(这就是鸡尾酒排序)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | const cooktailSort = (arr) => { let min = 0; let max = arr.length - 1; while(min < max){ for(let j = min;j < max;j++){ if(arr[j] > arr[j+1]){ let tmp = arr[j]; arr[j] = arr[j+1]; arr[j+1] = tmp; } } -- max; for(let j = max;j > min;j--){ if(arr[j] < arr[j-1]){ let tmp = arr[j] arr[j] = arr[j-1]; arr[j-1] = tmp; } } ++ min; } return arr; } |
算法分析
冒泡排序对有 $n$ 个元素的项目平均需要 $O(n^2)$ 次比较次数,它可以原地排序,并且是能简单实现的几种排序算法之一,但是它对于少数元素之外的数列排序是很没有效率的。
- 最佳情况: $T(n) = O(n)$
- 最差情况: $T(n) = O(n^2)$
- 平均情况: $T(n) = O(n^2)$
选择排序(Selection sort)[2]
算法原理
选择排序(Selection sort)是一种简单直观的排序算法。它的工作原理如下。首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
图解如下:

算法描述与实现
- 具体算法描述如下:
$n$ 个记录的直接选择排序可经过 $n - 1$ 趟直接选择排序得到有序结果。具体算法描述如下:
- 初始状态:无序区为
R[1 ... n],有序区为空; - 第 $i$ 趟排序$(i = 1, 2, 3 ... n - 1)$开始时,当前有序区和无序区分别为 $R[1 ... i - 1]$ 和 $R(i ... n)$。该趟排序从当前无序区中选出关键字最小的记录 $R[k]$,将它与无序区的第 1 个记录 $R$ 交换,使 $R[1 ... i]$ 和 $R[i + 1 ... n]$ 分别变为记录个数增加 1 个的新有序区和记录个数减少 1 个的新无序区;
- $n - 1$ 趟结束后,数组有序化。
- 代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | const SelectionSort = (arr) => { let len = arr.length; let minIndex, tmp; console.time('选择排序耗时'); for (let i = 0;i < len - 1; i++){ minIndex = i; for(let j = i + 1;j < len;j++){ if(arr[minIndex] > arr[j]){ minIndex = j; } } tmp = arr[i]; arr[i] = arr[minIndex]; arr[minIndex] = tmp; } console.timeEnd('选择排序耗时'); return arr; } |
算法分析
选择排序的主要优点与数据移动有关。如果某个元素位于正确的最终位置上,则它不会被移动。选择排序每次交换一对元素,它们当中至少有一个将被移到其最终位置上,因此对 $n$ 个元素的表进行排序总共进行至多 $n - 1$ 次交换。在所有的完全依靠交换去移动元素的排序方法中,选择排序属于非常好的一种。 但原地操作几乎是选择排序的唯一优点,当空间复杂度要求较高时,可以考虑选择排序;实际适用的场合非常罕见。
- 最佳情况: $T(n) = O(n^2)$
- 最差情况: $T(n) = O(n^2)$
- 平均情况: $T(n) = O(n^2)$
插入排序(Insertion sort)[3]
算法原理
插入排序(Insertion Sort)是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前s扫描,找到相应位置并插入。插入排序在实现上,通常采用 in-place 排序(即只需用到 $O(1)$ 的额外空间的排序),因而在从后向前的扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
图解如下:

算法描述与实现
- 具体算法描述如下:
一般来说,插入排序都采用in-place在数组上实现。具体算法描述如下:
- 从第一个元素开始,该元素可以认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后向前扫描
- 如果该元素(已排序)大于新元素,将该元素移到下一位置
- 重复步骤 3,直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插入到该位置后
- 重复步骤 $2~5$
如果比较操作的代价比交换操作大的话,可以采用二分查找法来减少比较操作的数目。该算法可以认为是插入排序的一个变种,称为二分查找插入排序。
- 代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | const insertionSort = (arr) => { let len = arr.length; console.time('插入排序耗时'); for (let i = 1;i < len; i++){ let key = arr[i]; let j = i - 1; while(j >= 0 && arr[j] > key){ arr[j+1] = arr[j]; j--; } arr[j+1] = key; } console.timeEnd('插入排序耗时'); return arr; } |
改进插入排序:查找插入位置时使用二分查找的方式。
具体思路如下:
- 在插入第 $i$ 个元素时,对前面的 $0 ~ i-1$ 元素进行折半。
- 与前面的 $0 ~ i-1$ 个元素中间的元素进行比较,如果小,则对前半再进行折半,否则对后半进行折半。
- 直到 left > right,再把第 $i$ 个元素前 1 位和目标位置间的所有元素后移,把第 $i$ 个元素放在目标位置上。
- 代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | const binaryInsertionSort = (arr) => { console.time('二分插入排序耗时:'); for (let i = 1; i < arr.length; i++){ let key = arr[i], left = 0, right = i - 1; while (left <= right){ let middle = parseInt((left + right) / 2); if (key < arr[middle]){ right = middle - 1; }else{ left = middle + 1; } } for (let j = i - 1; j >= left; j--){ arr[j + 1] = arr[j]; } arr[left] = key; } console.timeEnd('二分插入排序耗时:'); return arr; } |
算法分析
- 最佳情况: $T(n) = O(n)$
- 最差情况: $T(n) = O(n^2)$
- 平均情况: $T(n) = O(n^2)$
希尔排序(Shell sort)[4]
算法原理
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。它是非稳定排序算法。
希尔排序基于插入排序的以下两点性质提出了改进方法:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率。
- 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位。
它与插入排序的不同之处在于,它会优先比较距离较远的元素。因此希尔排序又叫缩小增量排序。
图解如下:

算法描述与实现
- 具体算法描述如下:
先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,具体算法描述:
- 选择一个增量序列$t1,t2,…,tk$,其中 $ti > tj(i > j)$,$tk = 1$;
- 按增量序列个数 $k$,对序列进行 $k$ 趟排序;
- 每趟排序,根据对应的增量 $ti$,将待排序列分割成若干长度为 $m$ 的子序列,分别对各子表进行直接插入排序。仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
- 代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | const shellSort = (arr) => { console.time('希尔排序耗时:'); let len = arr.length,temp,gap = 1; while(gap < len / 5) { // 动态定义间隔序列步长为 5 gap = gap * 5 + 1; } for (gap; gap > 0; gap = Math.floor(gap / 5)) { for (let i = gap; i < len; i++) { temp = arr[i]; let j; for (j = i - gap; j >= 0 && arr[j] > temp; j -= gap) { arr[j + gap] = arr[j]; } arr[j + gap] = temp; } } console.timeEnd('希尔排序耗时:'); return arr; } |
算法分析
- 最佳情况: $T_(n) = O_(n\log_2 n)$
- 最差情况: $T_(n) = O_(n\log_2 n)$
- 平均情况: $T_(n) = O_(n\log n)$
归并排序(Merge sort)[5]
算法原理
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。归并排序是一种稳定的排序方法。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
图解如下:

算法描述与实现
- 具体算法描述如下:
- 把长度为 n 的输入序列分成两个长度为 n/2 的子序列;
- 对这两个子序列分别采用归并排序;
- 将两个排序好的子序列合并成一个最终的排序序列。
- 代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | const mergeSort = (arr) =>{ //采用自上而下的递归方法 let len = arr.length; if(len < 2) { return arr; } let middle = Math.floor(len / 2), left = arr.slice(0, middle), right = arr.slice(middle); return merge(mergeSort(left), mergeSort(right)); } const merge = (left, right) => { let result = []; while (left.length && right.length) { if (left[0] <= right[0]) { result.push(left.shift()); } else { result.push(right.shift()); } } while (left.length) result.push(left.shift()); while (right.length) result.push(right.shift()); return result; } let arr=[3,44,38,5,47,15,36,26,27,2,46,4,19,50,48]; console.time('归并排序耗时'); console.log(mergeSort(arr)); console.timeEnd('归并排序耗时'); |
算法分析
和选择排序一样,归并排序的性能不受输入数据的影响,但它的表现比选择排序要好,因为它始终都是 $O_(n\log n)$ 的时间复杂度。但代价是需要额外的内存空间。
- 最佳情况: $T_(n) = O_(n)$
- 最差情况: $T_(n) = O_(n\log n)$
- 平均情况: $T_(n) = O_(n\log n)$
快速排序(Quick sort)[6]
算法原理
通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。

算法描述与实现
- 具体算法描述如下:
快速排序使用分治法来把一个串(list)分为两个子串(sub-lists)。具体算法描述如下:
- 从数列中挑出一个元素,称为 “基准”(pivot);
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
- 代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | const quickSort = (arr) => { if (arr.length <= 1) { return arr; } let pivotIndex = Math.floor(arr.length / 2); let pivot = arr.splice(pivotIndex, 1)[0]; let left = []; let right = []; for (let i = 0; i < arr.length; i++){ if (arr[i] < pivot) { left.push(arr[i]); } else { right.push(arr[i]); } } return quickSort(left).concat([pivot], quickSort(right)); }; let arr=[3,44,38,5,47,15,36,26,27,2,46,4,19,50,48]; console.time('快速排序耗时'); console.log(quickSort(arr)); console.timeEnd('快速排序耗时'); |
算法分析
- 最佳情况: $T_(n) = O_(n\log n)$
- 最差情况: $T_(n) = O_(n^2)$
- 平均情况: $T_(n) = O_(n\log n)$
堆排序(Heap sort)[7]
算法原理
堆排序可以说是一种利用堆的概念来排序的选择排序。它利用堆这种数据结构所设计。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。

算法描述与实现
- 具体算法描述如下:
- 将初始待排序关键字序列 $(R1,R2…,Rn)$ 构建成大顶堆,此堆为初始的无序区;
- 将堆顶元素 $R[1]$ 与最后一个元素 $R[n]$ 交换,此时得到新的无序区 $(R1,R2,……,Rn-1)$ 和新的有序区 $(Rn)$ ,且满足 $R[1,2…,n-1] <= R[n]$;
- 由于交换后新的堆顶 $R[1]$ 可能违反堆的性质,因此需要对当前无序区 $(R1,R2,……,Rn-1)$ 调整为新堆,然后再次将 $R[1]$ 与无序区最后一个元素交换,得到新的无序区 $(R1,R2…,Rn-2)$ 和新的有序区 $(Rn-1,Rn)$。不断重复此过程直到有序区的元素个数为 n-1,则整个排序过程完成。
- 代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | const heapSort = (array) => { console.time('堆排序耗时'); //建堆 let heapSize = array.length, temp; for (let i = Math.floor(heapSize / 2) - 1; i >= 0; i--) { heapify(array, i, heapSize); } //堆排序 for (let j = heapSize - 1; j >= 1; j--) { temp = array[0]; array[0] = array[j]; array[j] = temp; heapify(array, 0, --heapSize); } console.timeEnd('堆排序耗时'); return array; } /*方法说明:维护堆的性质 @param arr 数组 @param x 数组下标 @param len 堆大小*/ const heapify = (arr, x, len) => { let l = 2 * x + 1, r = 2 * x + 2, largest = x, temp; if (l < len && arr[l] > arr[largest]) { largest = l; } if (r < len && arr[r] > arr[largest]) { largest = r; } if (largest != x) { temp = arr[x]; arr[x] = arr[largest]; arr[largest] = temp; heapify(arr, largest, len); } } let arr=[91,60,96,13,35,65,46,65,10,30,20,31,77,81,22]; console.log(heapSort(arr)); |
算法分析
- 最佳情况: $T_(n) = O_(n\log n)$
- 最差情况: $T_(n) = O_(n\log n)$
- 平均情况: $T_(n) = O_(n\log n)$
计数排序(Counting sort)[8]
算法原理
计数排序(Counting sort)是一种稳定的排序算法。计数排序使用一个额外的数组 C,其中第 i 个元素是待排序数组 A 中值等于 i 的元素的个数。然后根据数组 C 来将 A 中的元素排到正确的位置。它只能对整数进行排序。

算法描述与实现
- 具体算法描述如下:
- 找出待排序的数组中最大和最小的元素;
- 统计数组中每个值为 i 的元素出现的次数,存入数组 C 的第 i 项;
- 对所有的计数累加(从 C 中的第一个元素开始,每一项和前一项相加);
- 反向填充目标数组:将每个元素 i 放在新数组的第 $C(i)$ 项,每放一个元素就将 $C(i)$ 减去 1。
- 代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | const countingSort = (array) => { let len = array.length, result = [], C = [], min,max; min = max = array[0]; console.time('计数排序耗时'); for (let i = 0; i < len; i++) { min = min <= array[i] ? min : array[i]; max = max >= array[i] ? max : array[i]; C[array[i]] = C[array[i]] ? C[array[i]] + 1 : 1; } for (let j = min; j < max; j++) { C[j + 1] = (C[j + 1] || 0) + (C[j] || 0); } for (let k = len - 1; k >= 0; k--) { result[C[array[k]] - 1] = array[k]; C[array[k]]--; } console.timeEnd('计数排序耗时'); return result; } let arr = [2, 2, 3, 8, 7, 1, 2, 2, 2, 7, 3, 9, 8, 2, 1, 4, 2, 4, 6, 9, 2]; console.log(countingSort(arr)); |
算法分析
计数排序的核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。 作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。
当输入的元素是 n 个 0 到 k 之间的整数时,它的运行时间是 O(n + k)。计数排序不是比较排序,排序的速度快于任何比较排序算法。由于用来计数的数组 C 的长度取决于待排序数组中数据的范围(等于待排序数组的最大值与最小值的差加上 1),这使得计数排序对于数据范围很大的数组,需要大量时间和内存。
- 最佳情况: $T_(n) = O_(n+k)$
- 最差情况: $T_(n) = O_(n+k)$
- 平均情况: $T_(n) = O_(n+k)$
桶排序(Bucket sort)[9]
算法原理
工作的原理是将数组分到有限数量的桶里。每个桶再个别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序)
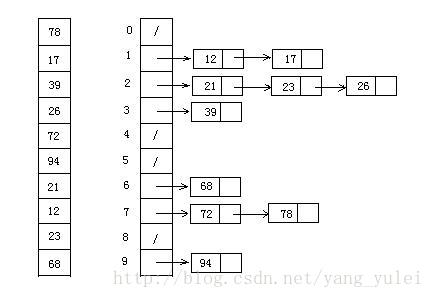
算法描述与实现
- 具体算法描述如下:
- 设置一个定量的数组当作空桶;
- 遍历输入数据,并且把数据一个一个放到对应的桶里去;
- 对每个不是空的桶进行排序;
- 从不是空的桶里把排好序的数据拼接起来。
- 代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | const bucketSort = (array, num) => { if (array.length <= 1) { return array; } var len = array.length, buckets = [], result = [], min = max = array[0], regex = '/^[1-9]+[0-9]*$/', space, n = 0; num = num || ((num > 1 && regex.test(num)) ? num : 10); console.time('桶排序耗时'); for (var i = 1; i < len; i++) { min = min <= array[i] ? min : array[i]; max = max >= array[i] ? max : array[i]; } space = (max - min + 1) / num; for (var j = 0; j < len; j++) { var index = Math.floor((array[j] - min) / space); if (buckets[index]) { // 非空桶,插入排序 var k = buckets[index].length - 1; while (k >= 0 && buckets[index][k] > array[j]) { buckets[index][k + 1] = buckets[index][k]; k--; } buckets[index][k + 1] = array[j]; } else { //空桶,初始化 buckets[index] = []; buckets[index].push(array[j]); } } while (n < num) { result = result.concat(buckets[n]); n++; } console.timeEnd('桶排序耗时'); return result; } var arr=[3,44,38,5,47,15,36,26,27,2,46,4,19,50,48]; console.log(bucketSort(arr,4)); |
算法分析
桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。 桶排序最好情况下使用线性时间 $O(n)$,桶排序的时间复杂度,取决与对各个桶之间数据进行排序的时间复杂度,因为其它部分的时间复杂度都为 $O(n)$。很显然,桶划分的越小,各个桶之间的数据越少,排序所用的时间也会越少。但相应的空间消耗就会增大。
- 最佳情况: $T_(n) = O_(n+k)$
- 最差情况: $T_(n) = O_(n+k)$
- 平均情况: $T_(n) = O_(n^2)$
基数排序(Radix sort)[10]
算法原理
基数排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前。基数排序基于分别排序,分别收集,所以是稳定的。

算法描述与实现
- 具体算法描述如下:
- 取得数组中的最大数,并取得位数;
- arr 为原始数组,从最低位开始取每个位组成 radix 数组;
- 对 radix 进行计数排序(利用计数排序适用于小范围数的特点);
- 代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | const radixSort = (arr, maxDigit) => { var mod = 10; var dev = 1; var counter = []; console.time('基数排序耗时'); for (var i = 0; i < maxDigit; i++, dev *= 10, mod *= 10) { for(var j = 0; j < arr.length; j++) { var bucket = parseInt((arr[j] % mod) / dev); if(counter[bucket]== null) { counter[bucket] = []; } counter[bucket].push(arr[j]); } var pos = 0; for(var j = 0; j < counter.length; j++) { var value = null; if(counter[j]!=null) { while ((value = counter[j].shift()) != null) { arr[pos++] = value; } } } } console.timeEnd('基数排序耗时'); return arr; } var arr = [3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48]; console.log(radixSort(arr,2)); |
算法分析
基数排序有两种方法:
MSD 从高位开始进行排序 LSD 从低位开始进行排序
- 最佳情况: $T_(n) = O_(n^2)$
- 最差情况: $T_(n) = O_(n^2)$
- 平均情况: $T_(n) = O_(n^2)$
基数排序 vs 计数排序 vs 桶排序
这三种排序算法都利用了桶的概念,但对桶的使用方法上有明显差异:
基数排序:根据键值的每位数字来分配桶 计数排序:每个桶只存储单一键值 桶排序:每个桶存储一定范围的数值
以上代码可访问 GitHub 具体查看
JS 原生函数中的排序
说到前端排序,自然首先会想到 JavaScript 的原生接口 Array.prototype.sort
这个接口自 ECMAScript 1st Edition 起就被设计存在。而在规范中关于它的描述是这样的:[11]
Array.prototype.sort(compareFn)
The elements of this array are sorted. The sort is not necessarily stable (that is, elements that compare equal do not necessarily remain in their original order). If comparefn is not undefined, it should be a function that accepts two arguments x and y and returns a negative value if x < y, zero if x = y, or a positive value if x > y.
显然,规范里并没有限定 sort 内部需要用什么排序算法。在这样的背景下,前端排序这件事完全取决于各家浏览器内核的具体实现。
Chrome 的实现
Chrome 的 JavaScript 引擎是 v8。由于它是开源的,所以可以直接看源代码。
整个 array.js 都是用 JavaScript 语言实现的。排序方法部分很明显比通常看到的快速排序要复杂得多,但显然核心算法还是快速排序的思想。算法复杂的原因在于 v8 出于性能考虑进行了很多优化。(后续会展开说)
Firefox中的实现
暂时无法确定 Firefox 的 JavaScript 引擎即将使用的数组排序算法会是什么。
按照现有的信息,SpiderMoney 内部实现了归并排序。(这里不多做叙述)
Microsoft Edge中的实现
Microsoft Edge 的 JavaScript 引擎 Chakra 的核心部分代码已经于 2016 年初在 Github 开源。
通过源代码可以发现,Chakra 的数组排序算法也主要是以快速排序为主。并针对其他具体特殊情况进行具体优化。
排序的差异
如上所述,快速排序是一种不稳定的排序算法,而归并排序是一种稳定的排序算法。由于不同引擎在算法选择上可能存在差异,导致前端如果依赖 Array.prototype.sort 接口实现的 JavaScript 代码,在浏览器中实际执行的排序效果是不一致的。
而排序稳定性的差异其实也只是在特定的场景才会体现出问题;在很多情况下,不稳定的排序也并不会造成什么影响。所以假如实际项目开发中,对于数组的排序没有稳定性的需求,那么看到这里就可以了。
但是若项目要求排序必须是稳定的,那么这些差异的存在将无法满足需求。我们需要为此进行一些额外的工作。
举个例子:
某市的机动车牌照拍卖系统,最终中标的规则为:
1 2 | 1. 按价格进行倒排序; 2. 相同价格则按照竞标顺位(即价格提交时间)进行正排序。 |
排序若是在前端进行,那么采用快速排序的浏览器中显示的中标者很可能是不符合预期的。
此外例如:
MySQL 5.6 的 limit M,N 语句实现
等情况都是不稳定排序的特征。
背后的原因
Chrome为什么采用快速排序
其实这个情况从一开始便存在。
Chrome测试版于2008年9月2日发布 (这里附上当时随版本发布的漫画,还是很有意思的Google on Google Chrome - comic book),然而发布后不久,就有开发者向 Chromium 开发组提交 #90 Bug V8 doesn't stable sort 反馈 v8 的数组排序实现不是稳定排序的。
这个 Bug ISSUE 讨论的时间跨度很大。时至今日,仍然有开发者对 v8 的数组排序的实现提出评论。
同时我们还注意到,该 ISSUE 曾经已被关闭。但是于 2013 年 6 月被开发组成员重新打开,作为 ECMAScript Next 规范讨论的参考。
而 es-discuss 的最后结论是这样的
It does not change. Stable is a subset of unstable. And vice versa, every unstable algorithm returns a stable result for some inputs. Mark’s point is that requiring “always unstable” has no meaning, no matter what language you chose.
这也正如本文前段所引用的已定稿 ECMAScript 2015 规范中的描述一样。
时代特点
IMHO,Chrome 发布之初即被报告出这个问题可能是有其特殊的时代特点。
上文已经说到,Chrome 第一版是 2008 年 9 月发布的。根据 statcounter 的统计数据,那个时期市场占有率最高的两款浏览器分别是 IE(那时候只有 IE6 和 IE7) 和 Firefox,市场占有率分别达到了 67.16% 和 25.77%。也就是说,两个浏览器加起来的市场占有率超过了 90%。
而根据另一份浏览器排序算法稳定性的统计数据显示,这两款超过了 90% 市场占有率的浏览器都采用了稳定的数组排序。所以 Chrome 发布之初被开发者质疑也是合情合理的。
我们从 ISSUE 讨论的过程中,可以大概理解开发组成员对于引擎实现采用快速排序的一些考量。他们认为引擎必须遵守 ECMAScript 规范。由于规范不要求稳定排序的描述,故他们认为 v8 的实现也是完全符合规范的。
性能考虑
另外,他们认为 v8 设计的一个重要考量在于引擎的性能。
快速排序相比较于归并排序,在整体性能上表现更好:
- 更高的计算效率。快速排序在实际计算机执行环境中比同等时间复杂度的其他排序算法更快(不命中最差组合的情况下)
- 更低的空间成本。前者仅有 $O(logn)$ 的空间复杂度,相比较后者 $O(n)$ 的空间复杂度在运行时的内存消耗更少
v8 在数组排序算法中的性能优化
既然说 v8 非常看中引擎的性能,那么在数组排序中它做了哪些事呢?
通过阅读源代码,还是粗浅地学习了一些皮毛。
- 混合插入排序 快速排序是分治的思想,将大数组分解,逐层往下递归。但是若递归深度太大,为了维持递归,调用栈的内存资源消耗也会很大。优化不好甚至可能造成栈溢出。
目前 v8 的实现是设定一个阈值,对最下层的 10 个及以下长度的小数组使用插入排序。
根据代码注释以及 Wikipedia 中的描述,虽然插入排序的平均时间复杂度为 $O(n^2)$ 差于快速排序的 $O(nlogn)$。但是在运行环境,小数组使用插入排序的效率反而比快速排序会更高,这里不再展开。
1 2 3 4 5 6 7 8 9 10 11 12 | var QuickSort = function QuickSort(a, from, to) { ...... while (true) { // Insertion sort is faster for short arrays. if (to - from <= 10) { InsertionSort(a, from, to); return; } ...... } ...... }; |
- 三数取中
正如已知的,快速排序的阿克琉斯之踵在于,最差数组组合情况下会算法退化。
快速排序的算法核心在于选择一个基准(pivot),将经过比较交换的数组按基准分解为两个数区进行后续递归。试想如果对一个已经有序的数组,每次选择基准元素时总是选择第一个或者最后一个元素,那么每次都会有一个数区是空的,递归的层数将达到 n,最后导致算法的时间复杂度退化为 $O(n^2)$。因此 pivot 的选择非常重要。
v8采用的是**三数取中(median-of-three)**的优化:除了头尾两个元素再额外选择一个元素参与基准元素的竞争。
第三个元素的选取策略大致为:
- 当数组长度小于等于 1000 时,选择折半位置的元素作为目标元素。
- 当数组长度超过 1000 时,每隔 200-215 个(非固定,跟着数组长度而变化)左右选择一个元素来先确定一批候选元素。接着在这批候选元素中进行一次排序,将所得的中位值作为目标元素
最后取三个元素的中位值作为 pivot。
v8 代码示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | var GetThirdIndex = function(a, from, to) { var t_array = new InternalArray(); // Use both 'from' and 'to' to determine the pivot candidates. var increment = 200 + ((to - from) & 15); var j = 0; from += 1; to -= 1; for (var i = from; i < to; i += increment) { t_array[j] = [i, a[i]]; j++; } t_array.sort(function(a, b) { return comparefn(a[1], b[1]); }); var third_index = t_array[t_array.length >> 1][0]; return third_index; }; var QuickSort = function QuickSort(a, from, to) { ...... while (true) { ...... if (to - from > 1000) { third_index = GetThirdIndex(a, from, to); } else { third_index = from + ((to - from) >> 1); } } ...... }; |
- 原地排序
目前,大多数快速排序算法中大部分的代码实现如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | var quickSort = function(arr) { if (arr.length <= 1) { return arr; } var pivotIndex = Math.floor(arr.length / 2); var pivot = arr.splice(pivotIndex, 1)[0]; var left = []; var right = []; for (var i = 0; i < arr.length; i++){ if (arr[i] < pivot) { left.push(arr[i]); } else { right.push(arr[i]); } } return quickSort(left).concat([pivot], quickSort(right)); }; |
以上代码存在一个问题在于:利用 left 和 right 两个数区存储递归的子数组,因此它需要 $O(n)$ 的额外存储空间。这与理论上的平均空间复杂度 $O(logn)$ 相比差距较大。
额外的空间开销,同样会影响实际运行时的整体速度。(这也是快速排序在实际运行时的表现可以超过同等时间复杂度级别的其他排序算法的其中一个原因。)所以一般来说,性能较好的快速排序会采用原地(in-place)排序的方式。
v8 源代码中的实现是对原数组进行元素交换。
Firefox 为什么采用归并排序
它的背后也是有故事的。
Firefox 其实在一开始发布的时候对于数组排序的实现并不是采用稳定的排序算法,这块有据可考。
Firefox(Firebird) 最初版本实现的数组排序算法是堆排序,这也是一种不稳定的排序算法。因此,后来有人对此提交了一个 Bug。
Mozilla开发组内部针对这个问题进行了一系列讨论。
从讨论的过程我们能够得出几点
- 同时期 Mozilla 的竞争对手是 IE6,从上文的统计数据可知 IE6 是稳定排序的
- JavaScript 之父 Brendan Eich 觉得 Stability is good
- Firefox在采用堆排序之前采用的是快速排序
基于开发组成员倾向于实现稳定的排序算法为主要前提,Firefox3 将归并排序作为了数组排序的新实现。
解决排序稳定性的差异
以上说了这么多,主要是为了讲述各个浏览器对于排序实现的差异,以及解释为什么存在这些差异的一些比较表层的原因。
但是读到这里,读者可能还是会有疑问:如果我的项目就是需要依赖稳定排序,那该怎么办呢?
解决方案
其实解决这个问题的思路比较简单。
浏览器出于不同考虑选择不同排序算法。可能某些偏向于追求极致的性能,某些偏向于提供良好的开发体验,但是有规律可循。
从目前已知的情况来看,所有主流浏览器(包括IE6,7,8)对于数组排序算法的实现基本可以枚举:
- 归并排序 / Timsort
- 快速排序
所以,我们将快速排序经过定制改造,变成稳定排序的是不是就可以了?
一般来说,针对对象数组使用不稳定排序会影响结果。而其他类型数组本身使用稳定排序或不稳定排序的结果是相等的。因此方案大致如下:
- 将待排序数组进行预处理,为每个待排序的对象增加自然序属性,不与对象的其他属性冲突即可。
- 自定义排序比较方法 compareFn,总是将自然序作为前置判断相等时的第二判断维度。
面对归并排序这类实现时由于算法本身就是稳定的,额外增加的自然序比较并不会改变排序结果,所以方案兼容性比较好。
但是涉及修改待排序数组,而且需要开辟额外空间用于存储自然序属性,可想而知v8这类引擎应该不会采用类似手段。不过作为开发者自行定制的排序方案是可行的。
方案代码示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | ; const INDEX = Symbol('index'); function getComparer(compare) { return function (left, right) { let result = compare(left, right); return result === 0 ? left[INDEX] - right[INDEX] : result; }; } function sort(array, compare) { array = array.map( (item, index) => { if (typeof item === 'object') { item[INDEX] = index; } return item; } ); return array.sort(getComparer(compare)); } |
以上只是一个简单的满足稳定排序的算法改造示例。
之所以说简单,是因为实际生产环境中作为数组输入的数据结构冗杂,需要根据实际情况判断是否需要进行更多样的排序前类型检测。
选择排序算法的参考方法:
影响排序的因素有很多,平均时间复杂度低的算法并不一定就是最优的。相反,有时平均时间复杂度高的算法可能更适合某些特殊情况。同时,选择算法时还得考虑它的可读性,以利于软件的维护。一般而言,需要考虑的因素有以下四点:
-
待排序的记录数目 n 的大小;
-
记录本身数据量的大小,也就是记录中除关键字外的其他信息量的大小;
-
关键字的结构及其分布情况;
-
对排序稳定性的要求。
设待排序元素的个数为 n。选择的大致方案如下:
- 当 n 较大,则应采用时间复杂度为 $O(nlogn)$ 的排序方法:快速排序、堆排序或归并排序。
- 快速排序:是目前基于比较的内部排序中被认为是最好的方法,当待排序的关键字是随机分布时,快速排序的平均时间最短;
- 堆排序:如果内存空间允许且要求稳定性的,
- 归并排序:它有一定数量的数据移动,所以我们可能过与插入排序组合,先获得一定长度的序列,然后再合并,在效率上将有所提高。
-
当 n 较大,内存空间允许,且要求稳定性则选择归并排序
-
当 n 较小,可采用直接插入或直接选择排序。
直接插入排序:当元素分布有序,直接插入排序将大大减少比较次数和移动记录的次数。
直接选择排序:元素分布有序,如果不要求稳定性,选择直接选择排序
-
一般不使用或不直接使用传统的冒泡排序。
-
基数排序: 它是一种稳定的排序算法,但有一定的局限性,最好满足:
- 关键字可分解。
- 记录的关键字位数较少,如果密集更好
- 如果是数字时,最好是无符号的,否则将增加相应的映射复杂度,可先将其正负分开排序。
参考资料 & 拓展阅读
Array.prototype.sort 随机排列数组的错误实现
本文版权归 yangzj1992 所有。来源青春样博客(qcyoung.com),商业转载请联系本人获得授权,非商业转载请注明出处。
本博客采用 Disqus 作为评论解决方案,目前 Disqus 经常被 GFW 封锁,若想参与评论请翻墙访问本站或将 disqus.com 添加至翻墙白名单。你也可以通过导航栏上的社交网站与我联系